As an electrical engineering major, computer notes don’t really work. Getting math into OneNote is even worse than getting math into Word, and so for most of undergrad I stuck to paper and pencil. In my last semester I decided to try using Markdown Notes to both organize notes in my machine learning class as well as practice my LaTeX. Unfortunately the website was not maintained well and after emailing the author several times with no response asking to help contribute (the bugs fixes and features I needed weren’t being worked on), I decided that this year I would try something different.
I set up an instance of Hyde, a Poole theme that runs on the Jekyll platform (the same platform that runs this blog). To separate posts into classes I used the generate categories plugin which allows me to create a “categories” page, as well as display categories in my sidebar menu. However, Github (wisely) does not allow arbitrary code execution on their site via plugins, so I had to create a separate branch for the public site. Using instructions at the sorry app blog, I created a rake file to publish the blog for me. Now when I get to class, I just create a post in the master branch and run “rake blog:publish” to push to the server.
If you’re interested in any of my notes feel free to check them out at notes.nateharada.com.
Amazon’s AWS offers a free tier that provides a year’s worth of a micro instance along with a decent amount of storage and other services. If you use an EBS volume for your instance you can easily upgrade your machine to more powerful instances for cheap. For the most part, the micro instance is plenty of power for basic development I do. However, occasionally I’ll need an extra boost. Most recently I ran into problems running cabal update during my Haskell learning adventures.
Sometimes a process will terminate for no reason - especially during compilation. If this happens to you, run dmesg and check for an “Out of Memory” error.
While you could shutdown the instance and upgrade to a larger version (for a price), an easier way is to temporarily add swap space. When a computer doesn’t have enough physical RAM, it can use swap space as virtual memory. While slower than hardware, this space lets you increase the physical memory seen by the machine.
Without further ado, let’s add some swap space:
First check to see if you have any swap space in the first place
sudo swapon -s
If you have no swap (as Ubuntu EC2 doesn’t), you should see an empty list
Filename Type Size Used Priority
Next double check your disk usage. The swap file is hard disk space, and if you don’t have enough this won’t work. Run df -h to get a human readable output.
If all goes according to plan you should be able to see the swap partition by running swapon -s
Filename Type Size Used Priority
/swapfile file 262140 0 -1
This file will disappear on reboot, making it good for when you need to run big jobs infrequently. If you want to make this swap permanent you can follow instructions at this DigitalOcean post.
When I decided to replace my old WordPress blog, I was torn on what platform would be best. My portfolio homepage was already hosted on Github Pages, and I liked the idea of version control and free hosting combined. WordPress was easy to use for basic blogging, but creating a site that felt personalized and not like a template was difficult for me. I settled on Jekyll with Github pages - it was free, there were good resources available, and it was a light and customizable static site generator.
I settled on the Poole theme Lanyon for my new blog, but I had to make some customizations to get the look I truly wanted. I removed the sidebar completely and created a page at “_includes/menu.html” to replace it. Although I liked the Lanyon design, I wanted an even more minimalist theme since I only had a few links for the navigation.
For those interested, you can find the source for my customizations on my github page, and a good tutorial for most of the setup I did on Joshua Lande’s blog.
Developing Virtually with Amazon EC2
Supporting Windows has historically been viewed as an unfortunate but necessary evil by software developers. Historically, the hardcore open source junkies targeted only *nix systems while everyone else supported both *nix and the more popular Windows architecture. This has begun to change as Apple gains market share, due in (large) part to the iPhone’s dominance in the mobile market and the fact that iOS development requires a Mac. With Macs (and thus Unix based systems) now more popular with the kids, fewer open source software maintainers are putting in the work to support Windows. The Jekyll project alone officially only supports OSX and Linux. In our case, Github pages offers an easy way to install their entire toolchain on your local machine, but only if you’re on an operating system that Jekyll supports.
As much as I love Linux, there are too many unsupported software packages for me to justify switching my machine over entirely. I could dual boot (pain in the ass), virtualize (hardware intensive), or buy a Mac (too expensive). That’s where Amazon’s web services come in to save the day. By using Amazon’s EC2 compute cluster, we can access a linux machine in the cloud for almost free (in fact, it is free for the first year).
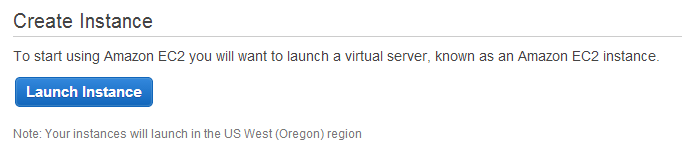
To get started, go ahead and sign up for Amazon EC2 and launch a new instance.
For the free tier we need to use the micro sized instance. If you for some reason think you want more computing power, feel free to pick another size. Remember that as long as you use an EBS storage instance you can resize your compute instance later if you need more or less power.
Once you have your new instance initialized, you can connect to it via SSH. Go to the “Instances” page and record your public DNS for your SSH client.
Amazon offers a guide to connecting via PuTTy for those of you who use it. Once you’re connected to your machine you can install the software packages you’ll need to develop using Jekyll. First, however, you’ll need to update your Ruby version or the software won’t build.
Now clone your blog’s repository and create a file in that directory called “Gemfile” that contains the following:
source'https://rubygems.org'
gem'github-pages'
then run bundle install to install all of the packages that Github uses on its servers.
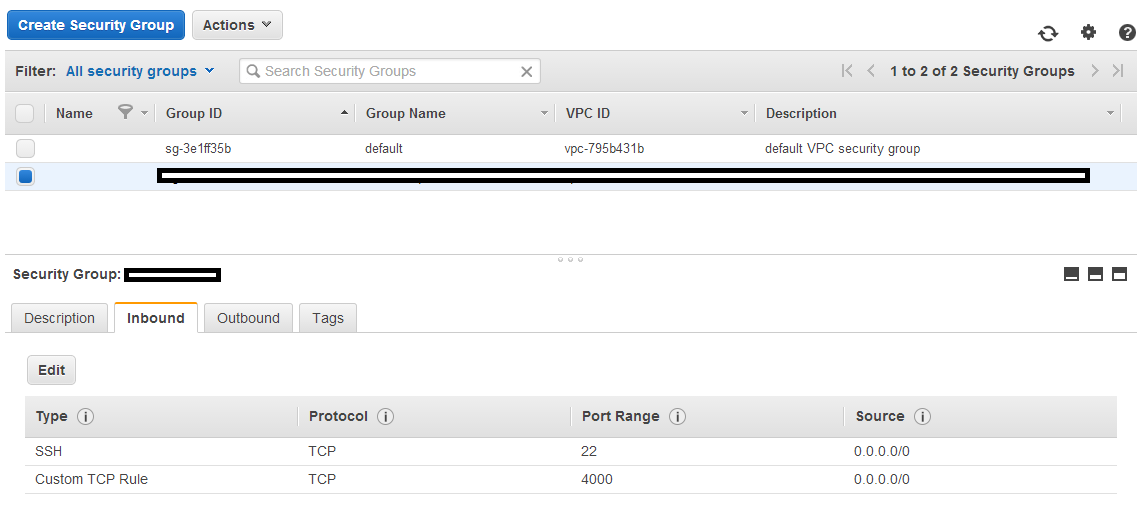
From here on out you can run Jekyll on your AWS instance via jekyll serve and connect to it by connecting to port 4000 of the public DNS address you found earlier. Note that to do this you’ll need to change the security policy of your machine to alow traffic through TCP port 4000.
Now you can do your development remotely and view changes in real time (as well as debugging information) without needing to install anything on your local machine. I use tmux and vim for my coding. I also created a CNAME rule with my domain name provider to redirect develop.nateharada.com to my AWS instance so I don’t need to keep entering the DNS name each time. Note that I leave my instance running 24/7, but if I stopped it the DNS name would likely change and this wouldn’t work.
I was in high school when my friend and I decided to attend our first music festival. It was a rainy August day that was somehow sweltering and uncomfortable in a way only Chicago can produce. My friend and I stepped up to the ticket window outside Grant Park and ordered our three day passes at the door.
There have been a few Lollapaloozas since that day, and in the time since, music festivals have exploded in popularity. Tickets this year sold out in record time and my hopes of getting even a one day were dashed by Europe’s lack of Wi-Fi and Sprint’s outrageous international data prices. In lieu of participating in three days of Chicago’s biggest music festival, I decided to take a look at some of the data behind Lollapalooza instead.
Getting the Data
The Lollapalooza website offers a good summary of the bands, as well as allows fans to create their own schedules. Each artist’s page shows how many fans have signed up, allowing us to get a good (albeit biased) view of an artist’s estimated attendance. I created a web scraper in Python, using the beautiful soup module to make the HTML parsing easier.
While the data on the website is nice, I wanted more information about each artist. Armed with a JSON file of artists and Lolla’s data (including fans, set times, and stage), I used The Echonest API to request additional metadata for each band. The Echonest is a fantastic company (based in my college town of Somerville), and their API offers an extensive set of metrics for both musical acts and individual songs.
A Look at Genres
Disclaimer: Nothing gets a bunch of music geeks angrier than someone trying to classify a bunch of hipster bands into genres. Bear with me on my classifications and feel free to argue in the comments.
The Echonest API offers a “terms” property that returns a list of genres sorted by how strongly they correspond to an artist. For each artist I took the top two from this list. I started by looking at the top words across all artists:
Top Words to Describe Artists:
75: rock
63: indie
36: pop
20: electronic
17: dance
16: alternative
etc…
As we can see, indie and rock are well represented at the top. However, this picture may be distorted because many genres are compounds (such as indie rock). If we switch from words to phrases we get a similar but slightly different picture. In technical terms, we have switched from a bag of words model to a vector space model. While bag of words represents each word separately, the vector space model is more generic and allows us to represent terms as multiple words:
Top Genres:
33: rock
26: indie
23: indie rock
21: pop
20: electronic
17: dance
etc…
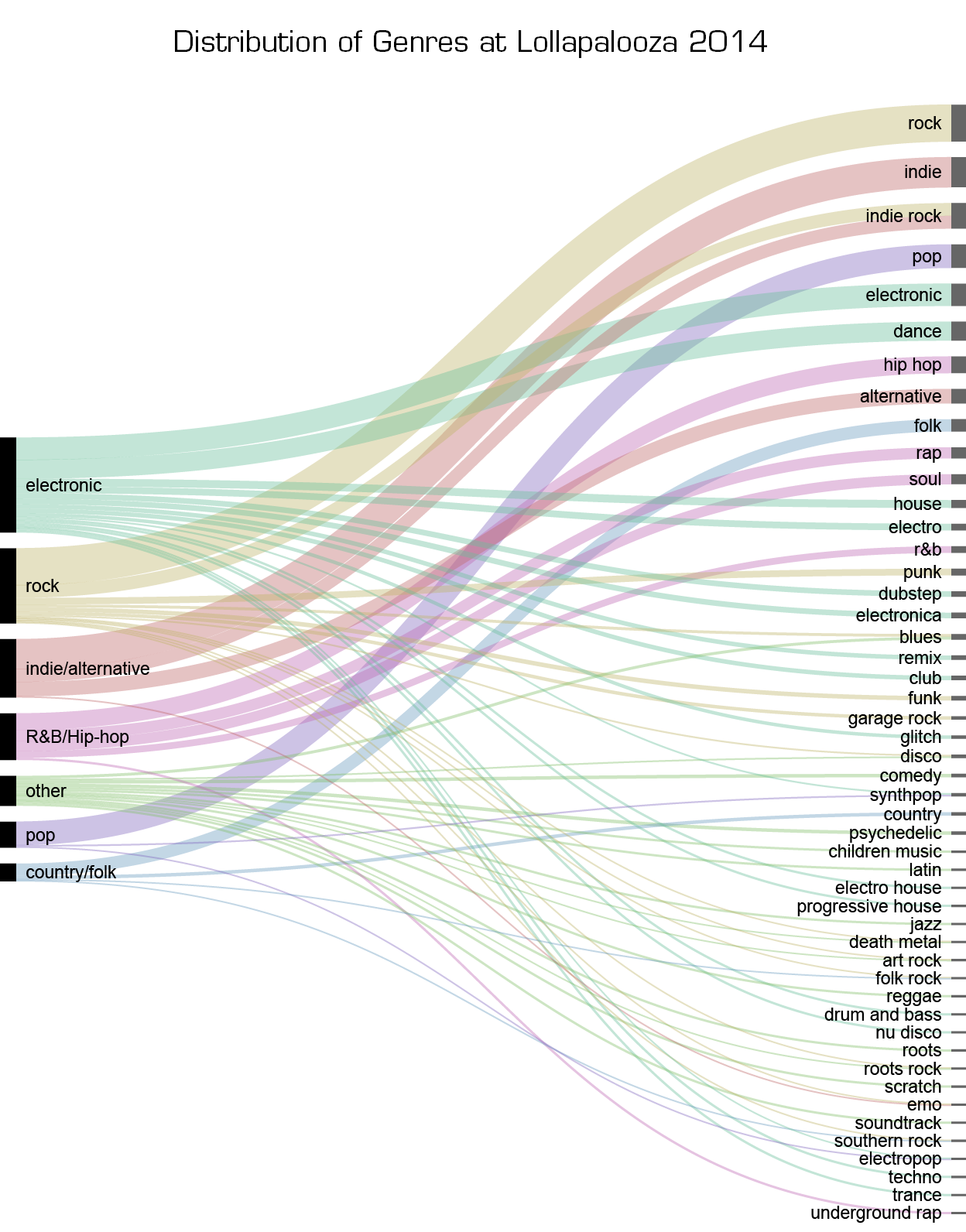
At the top, things look mostly the same. Pop is under-represented, however, owing to the large number of pop subgenres. It’s hard to truly get a feel of the larger “macro genres” at the festival using either of these models. I decided to classify (by hand) each genre into one or two of seven overarching genres. I used the fantastic RAW tools to create an alluvial diagram of how each genre corresponds to its larger parent:
In this case, the picture changes quite a bit. The multitude of different electronic genres sends the “electronic” category skyrocketing into first place. While my classification of genres obviously has significant sway on these rankings (who is to say all dance music is electronic), this view is consistent with the rise of EDM and the popularity of the DJ stage Perry’s at the festival.
A Look at Popularity
Artist popularity is a fickle thing - when I was in charge of concerts at Tufts a band could sell out popular dates in a few days if they hit it big on the radio. Talent management at Lollapalooza tries their best to extrapolate a band’s pull, but booking months in advance leaves room for error. This is part of the reason the schedule is released so late - organizers don’t know for sure which bands will be popular when they book.
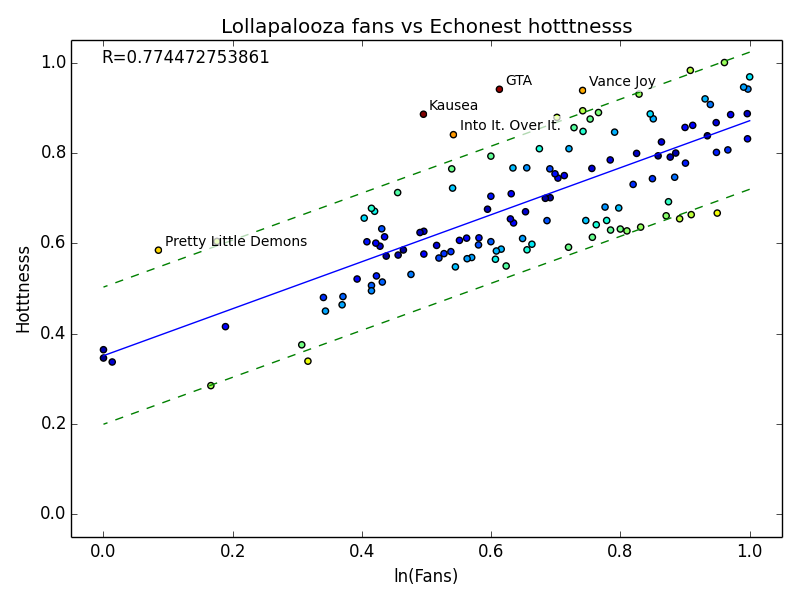
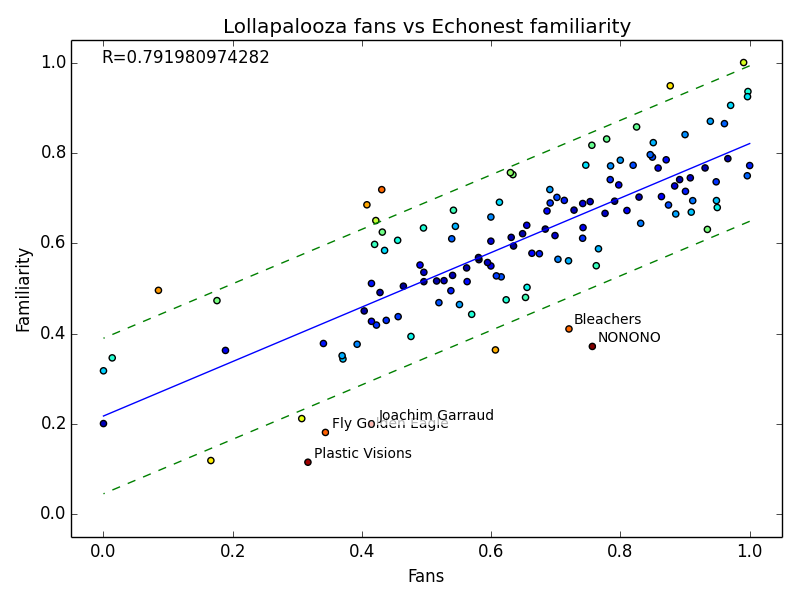
The Echonest offers two metrics of a band’s popularity - hotttnesss (yes spelled like that), and familiarity. Hotttness refers to the band’s instantaneous popularity based on blogs and music websites, while familiarity refers to a band’s popularity over time. In most cases the two are heavily correlated, but for older bands past their prime familiarity may far surpass popularity.
Based on these two metrics and number of fans attending a given show, we can see the top bands in each category (bold denotes headliners):
Top ten artists by number of fans on Lollapalooza.com
Lorde
Arctic Monkeys
Outkast
Foster The People
Eminem
Kings of Leon
Cage The Elephant
Calvin Harris
Young the Giant
GROUPLOVE
Top ten artists by hotttnesss via Echonest
Calvin Harris
Iggy Azalea
Lorde
Eminem
Arctic Monkeys
Duke Dumont
Vance Joy
Martin Garrix
Zedd
Skrillex
Top ten artists by familiarity via Echonest
Eminem
Nas
Arctic Monkeys
Outkast
Kings of Leon
Skrillex
Calvin Harris
Interpol
The Kooks
AFI
It seems festival organizers did pretty well. There is an understandable bias towards the more familiar artists over more immediately popular ones - organizers have no way to know who will be hottest come August and the more familiar the artist the safer choice they are. One interesting observation is that Lorde is the most popular according to Lolla fans. In terms of numbers, Lorde overshadows her headliner stage-mate The Arctic Monkeys (who are also rated quite high), although admittedly not by much. I suspect this discrepancy is due to Lorde’s continued radio success combined with her lack of American tour dates. Get to this stage early if you want any chance of a good seat for either band.
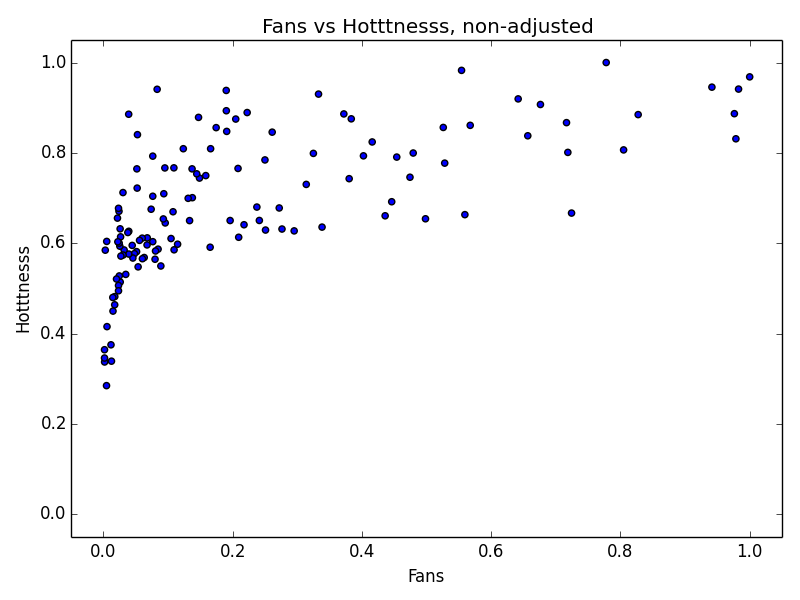
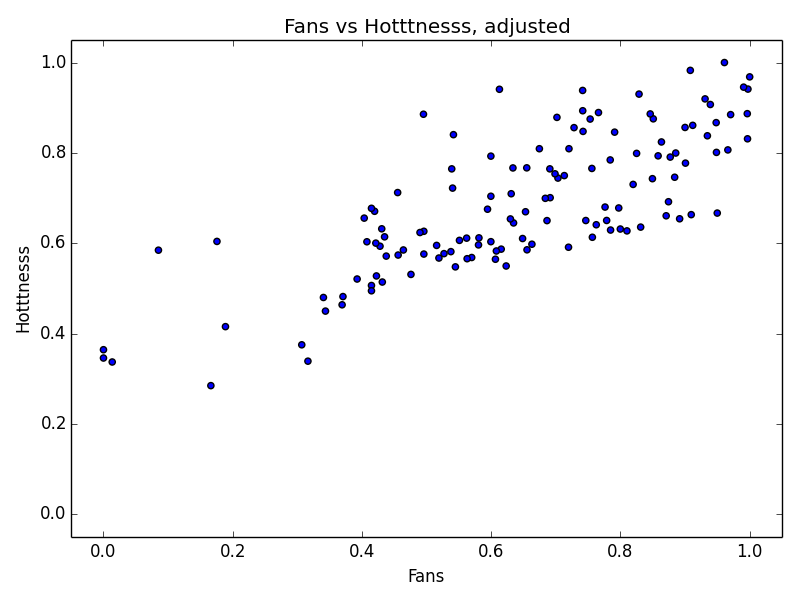
One question I had starting this analysis was whether or not Lolla’s fan base would have more esoteric (read: hipster) music tastes than the general population that Echonest is supposed to represent. I cynically believed that based on its massive popularity, Lollapalooza would in fact sway the other direction. By normalizing both fan numbers and hotttnesss (or familiarity) and plotting them against each other we can hopefully see if there is a difference.
Whoops. It looks like somewhere in The Echonest’s calculations they compress their scale, leading to the plot above. I took the logarithm of the fans and used that instead and got a much better result.
I fit a line to this data, as well as plotted one standard deviation above and below. The data points are color coded based on the (Euclidian) distance from the model, and the five largest outliers labeled.
In general the number of Lollapalooza fans is proportional to Echonest’s estimated popularity for both hotttnesss and familiarity. Fans tend to underattend the hotter concerts but overattend the less familiar, but for the most part stay within one standard deviation of the expectation. Although it’s only by a bit, we could potentially conclude that Lollapalooza is a bit more hipster than the Echonest public.
Disclaimers and Future Projects
Any data based project has to make assumptions about the population they are sampling. In this case, I assume that the Lollapalooza fans listed online accurately represents the entire population. This may not be the case - I know I never made a custom schedule when I attended Lolla so I’m not sure who does. It may correspond to a specific demographic or fans.
I’d love to have a second look at music festivals in general. One thing in particular I’d like to do is to look at a spectrum of music festivals across the nation and use document similarity techniques to try and create a plot of events based on how alike they are (either by bands or genres). The biggest hurdle for this is finding or creating a dataset with all the bands at each festival - I couldn’t find one online and each website is different making scraping difficult.
This is the first post in my new blog, and although I’ll be starting a busy school year soon, hopefully I’ll be able to do more these write-ups in the future. Feel free to leave questions or methodology complaints in the comments.
Python 2.7 is seriously lacking in support of 32-bit float wave files – the wave file module is shooting for support in 3.4 and the scipy.io.wavefile module have support unless you build from source. Which requires a FORTRAN compiler. Not my idea of fun just to support a feature that should be included out of the box.
For my current project I’ve been using the scikits.audiolab module to deal with my wave files. You’ll need the numpy/scipy installed, as well as setup tools, but once installed it’s really easy to work with.